What follows could have relevance to Multi-Dimensional Science / http://www.p2pfoundation.net/Multi-Dimensional_Science
Pattern theory, formulated by Ulf Grenander, is a mathematical formalism to describe knowledge of the world as patterns. It differs from other approaches to artificial intelligence in that it does not begin by prescribing algorithms and machinery to recognize and classify patterns; rather, it prescribes a vocabulary to articulate and recast the pattern concepts in precise language.
In addition to the new algebraic vocabulary, its statistical approach is novel in its aim to:
- Identify the hidden variables of a data set using real world data rather than artificial stimuli, which was previously commonplace.
- Formulate prior distributions for hidden variables and models for the observed variables that form the vertices of a Gibbs-like graph.
- Study the randomness and variability of these graphs.
- Create the basic classes of stochastic models applied by listing the deformations of the patterns.
- Synthesize (sample) from the models, not just analyze signals with it.
The Brown University Pattern Theory Group was formed in 1972 by Ulf Grenander. Many mathematicians are currently working in this group, noteworthy among them being the Fields Medalist David Mumford. Mumford regards Grenander as his "guru" in this subject.
Contents
[hide]Example: Natural Language Grammar[edit]
We begin with an example to motivate the algebraic definitions that follow.If we want to represent language patterns, the most immediate candidate for primitives might be words. However, set phrases, such as “in order to”, immediately indicate the inappropriateness of words as atoms. In searching for other primitives, we might try the rules of grammar. We can represent grammars as finite state automata or context-free grammars. Below is a sample finite state grammar automaton.


The following phrases are generated from a few simple rules of the automaton and programming code in pattern theory:
-
- the boy who owned the small cottage went to the deep forest
- the prince walked to the lake
- the girl walked to the lake and the princess went to the lake
- the pretty prince walked to the dark forest
-
- the evil evil prince walked to the lake
- the prince walked to the dark forest and the prince walked to a forest and the princess who lived in some big small big cottage who owned the small big small house went to a forest
Imagine that a configuration of generators are strung together linearly so its output forms a sentence, so each generator "bonds" to the generators before and after it. Denote these bonds as 1a,1b,2a,2b,…12a,12b. Each numerical label corresponds to the automaton's state and each letter "a" and "b" corresponds to the inbound and outbound bonds. Then the following bond table (left) is equivalent to the automaton diagram. For the sake of simplicity, only half of the bond table is shown—the table is actually symmetric.
| 1x | 1y | 2x | 2y | 3x | 3y | 4x | 4y | 5x | 5y | 6x | 6y | 7x | 7y | 8x | 8y | 9x | 9y | 10x | 10y | 11x | 11y | 12x | 12y | |
| 1x | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | 1 | - | - |
| 1y | - | 1 | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | |
| 2x | - | 1 | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | ||
| 2y | - | 1 | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | |||
| 3x | - | - | - | - | - | - | - | - | - | 1 | - | - | - | - | - | - | - | - | - | - | ||||
| 3y | - | 1 | - | - | - | - | - | - | - | 1 | - | - | - | - | - | - | - | - | - | |||||
| 4x | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | ||||||
| 4y | - | 1 | - | 1 | - | - | - | - | - | - | - | - | - | - | - | - | - | |||||||
| 5x | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | ||||||||
| 5y | - | 1 | - | - | - | - | - | - | - | - | - | - | - | - | - | |||||||||
| 6x | - | - | - | - | - | - | - | - | - | - | - | - | - | - | ||||||||||
| 6y | - | 1 | - | - | - | - | - | - | - | - | - | - | - | |||||||||||
| 7x | - | 1 | - | - | - | - | - | - | - | - | - | - | ||||||||||||
| 7y | - | - | - | - | - | - | - | - | - | - | - | |||||||||||||
| 8x | - | - | - | - | - | - | - | - | - | - | ||||||||||||||
| 8y | - | 1 | - | - | - | - | - | - | - | |||||||||||||||
| 9x | - | - | - | - | - | - | - | - | ||||||||||||||||
| 9y | - | 1 | - | - | - | - | - | |||||||||||||||||
| 10x | - | - | - | - | - | - | ||||||||||||||||||
| 10y | - | 1 | - | - | - | |||||||||||||||||||
| 11x | - | 1 | - | - | ||||||||||||||||||||
| 11y | - | 1 | - | |||||||||||||||||||||
| 12x | - | - | ||||||||||||||||||||||
| 12y | - |
A more sophisticated example can be found in the link grammar theory of natural language.
Algebraic foundations[edit]
Motivated by the example, we have the following definitions:1. A generator
 , drawn as
, drawn as
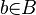 , which connects the
, which connects the  's to form a signal generator. 2 neighboring generators are connected when their bond values are the same. Similarity self-maps
's to form a signal generator. 2 neighboring generators are connected when their bond values are the same. Similarity self-maps 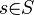 s: G -> G express the invariances of the world we are looking at, such as rigid body transformations, or scaling.
s: G -> G express the invariances of the world we are looking at, such as rigid body transformations, or scaling.2. Bonds glue generators into a configuration, c, which creates the signal against a backdrop Σ, with global features described locally by a bond coupling table called
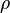 . The boolean function is the principal component of the regularity 4-tuple
. The boolean function is the principal component of the regularity 4-tuple  seems to capture the notion of allowable generator neighbors. That is, Regularity is the law of the stimulus domain defining, via a bond table, what neighbors are acceptable for a generator. It is the laws of the stimulus domain. Later, we will relax regularity from a boolean function to a probability value, it would capture what stimulus neighbors are probable.
seems to capture the notion of allowable generator neighbors. That is, Regularity is the law of the stimulus domain defining, via a bond table, what neighbors are acceptable for a generator. It is the laws of the stimulus domain. Later, we will relax regularity from a boolean function to a probability value, it would capture what stimulus neighbors are probable.Σ is the physical arrangement of the generators. In vision, it could be a 2-dimensional lattice. In language, it is a linear arrangement.
3. An image (C mod R) captures the notion of an observed Configuration, as opposed to one which exists independently from any perceptual apparatus. Images are configurations distinguished only by their external bonds, inheriting the configuration’s composition and similarities transformations. Formally, images are equivalence classes partitioned by an Identification Rule "~" with 3 properties:
- ext(c) = ext(c') whenever c~c'
- sc~sc' whenever c~c'
- sigma(c1,c2) ~ sigma(c1',c2') whenever c1~c1', c2~c2' are all regular.
4. A pattern is the repeatable components of an image, defined as the S-invariant subset of an image. Similarities are reference transformations we use to define patterns, e.g. rigid body transformations. At first glance, this definition seems suited for only texture patterns where the minimal sub-image is repeated over and over again. If we were to view an image of an object such as a dog, it is not repeated, yet seem like it seems familiar and should be a pattern. (Help needed here).
5. A deformation is a transformation of the original image that accounts for the noise in the environment and error in the perceptual apparatus. Grenander identifies 4 types of deformations: noise and blur, multi-scale superposition, domain warping, and interruptions.
- Example 2 Directed boundary
|





Again, just as in grammars, identifying the generators and bond tables require some thought. Just as subtle is the fact that a configuration is not the signal we observe. Rather, we observe its image as silhouette projections of the identification rule.
Topology[edit]
| This section is empty. You can help by adding to it. (December 2009) |
Entropy[edit]
Pattern Theory defines order in terms of the feature of interest given by p(c).- Energy(c) = −log P(c)
Statistics[edit]
Grenander’s Pattern Theory treatment of Bayesian inference in seems to be skewed towards on image reconstruction (e.g. content addressable memory). That is given image I-deformed, find I. However, Mumford’s interpretation of Pattern Theory is broader and he defines PT to include many more well-known statistical methods. Mumford’s criteria for inclusion of a topic as Pattern Theory are those methods "characterized by common techniques and motivations", such as the HMM, EM algorithm, dynamic programming circle of ideas. Topics in this section will reflect Mumford's treatment of Pattern Theory. His principle of statistical Pattern Theory are the following:- Use real world signals rather than constructed ones to infer the hidden states of interest.
- Such signals contain too much complexity and artifacts to succumb to a purely deterministic analysis, so employ stochastic methods too.
- Respect the natural structure of the signal, including any symmetries, independence of parts, marginals on key statistics. Validate by sampling from the derived models by and infer hidden states with Bayes’ rule.
- Across all modalities, a limited family of deformations distort the pure patterns into real world signals.
- Stochastic factors affecting an observation show strong conditional independence.
The generic set up is the following: Let s = the hidden state of the data that we wish to know. i = observed image. Bayes theorem gives
-
- p (s | i ) p(i) = p (s, i ) = p (i|s ) p(s)
- To analyze the signal (recognition): fix i, maximize p, infer s.
- To synthesize signals (sampling): fix s, generate i's, compare w/ real world images
Conditional probability for local properties[edit]
N-gram Text Strings: See Mumford's Pattern Theory by Examples, Chapter 1.MAP ~ MDL (MDL offers a glimpse of why the MAP probabilistic formulation make sense analytically)
[edit]
Bayes Theorem for Machine translation[edit]
Supposing we want to translate French sentences to English. Here, the hidden configurations are English sentences and the observed signal they generate are French sentences. Bayes theorem gives p(e|f)p(f) = p(e, f) = p(f|e)p(e) and reduces to the fundamental equation of machine translation: maximize p(e|f) = p(f|e)p(e) over the appropriate e (note that p(f) is independent of e, and so drops out when we maximize over e). This reduces the problem to three main calculations for:- p(e) for any given e, using the N-gram method and dynamic programming
- p(f|e) for any given e and f, using alignments and an expectation-maximization (EM) algorithm
- e that maximizes the product of 1 and 2, again, using dynamic programming
We now focus on p(f|e) in the three-part decomposition above. The other two parts, p(e) and maximizing e, uses similar techniques as the N-gram model. Given a French-English translation from a large training data set (such data sets exists from the Canadian parliament),
NULL And the program has been implemented
Le programme a ete mis en application
the sentence pair can be encoded as an alignment (2, 3, 4, 5, 6, 6, 6) that reads as follows: the first word in French comes from the second English word, the second word in French comes from the 3rd English word, and so forth. Although an alignment is a straight forward encoding of the translation, a more computationally convenient approach to an alignment is to break it down into four parameters:- Fertility: the number of words in the French string that will be connected to it. E.g. n( 3 | implemented ) = probability that “implemented” translates into three words – the word’s fertility
- Spuriousness: we introduce the artifact NULL as a word to represent the probability of tossing in a spurious French word. E.g. p1 and its complement will be p0 = 1 − p1.
- Translation: the translated version of each word. E.g. t(a | has ) = translation probability that the English "has" translates into the French "a".
- Distortion: the actual positions in the French string that these words will occupy. E.g. d( 5 | 2, 4, 6 ) = distortion of second position French word moving into the fifth position English word for a four-word English sentence and a six-word French sentence. We encode the alignments this way to easily represent and extract priors from our training data and the new formula becomes
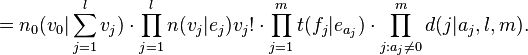
b c b c b
| | x |
x y x y y
called Parallel, Crossed, and Singleton respectively.To illustrate an EM algorithm, first set the desired parameter uniformly, that is
- t(x | b ) = t(y | b ) = t(x | c ) = t(y | c ) = 1⁄2
 The alignment probability for the “crossing alignment” (where b connects to y) got a boost from the second sentence pair b/y. That further solidified t(y | b), but as a side effect also boosted t(x | c), because x connects to c in that same “crossing alignment.” The effect of boosting t(x | c) necessarily means downgrading t(y | c) because they sum to one. So, even though y and c co-occur, analysis reveals that they are not translations of each other. With real data, EM also is subject to the usual local extremum traps.
The alignment probability for the “crossing alignment” (where b connects to y) got a boost from the second sentence pair b/y. That further solidified t(y | b), but as a side effect also boosted t(x | c), because x connects to c in that same “crossing alignment.” The effect of boosting t(x | c) necessarily means downgrading t(y | c) because they sum to one. So, even though y and c co-occur, analysis reveals that they are not translations of each other. With real data, EM also is subject to the usual local extremum traps.HMMs for speech recognition[edit]
For decades, speech recognition seemed to hit an impasse as scientists sought descriptive and analytic solution. The sound wave p(t) below is produced by speaking the word “ski”.
Its four distinct segments has very different characteristics. One can choose from many levels of generators (hidden variables): the intention of the speaker’s brain, the state of the mouth and vocal cords, or the ‘phones’ themselves. Phones are the generator of choice to be inferred and it encodes the word in a noisy, highly variable way. Early work on speech recognition attempted to make this inference deterministically using logical rules based on binary features extracted from p(t). For instance, the table below shows some of the features used to distinguish English consonants.
In real situations, the signal is further complicated by background noises such as cars driving by or artifacts such as a cough in mid sentence (mumford’s 2nd underpinning). The deterministic rule-based approach failed and the state of the art (e.g. Dragon Naturally Speaking) is to use a family of precisely tuned HMMs and a Bayesian MAP estimators to do better. Similar stories played out in vision, and other stimulus categories.
| p | t | k | b | d | g | m | n | f | s | v | z | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Continuant | - | - | - | - | - | - | - | - | + | + | + | + |
| Voiced | - | - | - | + | + | + | + | + | - | - | + | + |
| Nasal | - | - | - | - | - | - | + | + | - | - | - | - |
| Labial | + | - | - | + | - | - | + | - | + | - | + | - |
| Coronal | - | + | - | - | + | - | - | + | - | + | - | + |
| Anterior | + | + | - | + | + | - | + | + | + | + | + | + |
| Strident | - | - | - | - | - | - | - | - | + | + | + | + |
| (See Mumford's Pattern Theory: the mathematics of perception) The Markov stochastic process is diagrammed as follows: |

Further reading[edit]
- 2007. Ulf Grenander and Michael Miller Pattern Theory: From Representation to Inference. Oxford University Press. Paperback. (ISBN 9780199297061)
- 1994. Ulf Grenander General Pattern Theory. Oxford Science Publications. (ISBN 978-0198536710)
- 1996. Ulf Grenander Elements of Pattern Theory. Johns Hopkins University Press. (ISBN 978-0801851889)
See also[edit]
- Abductive reasoning
- Algebraic statistics
- Formal concept analysis
- Grammar Induction
- Image analysis
- Induction
- Lattice theory
- Spatial statistics
External links[edit]
- Pattern Theory Group at Brown University
- David Mumford, Pattern Theory By Example (in progress) Link is broken
- Brown et al. 1993, The Mathematics of Statistical Machine Translation: Parameter Estimation
- Pattern Theory: Grenander's Ideas and Examples - a video lecture by David Mumford
- Pattern Theory and Applications - graduate course page with material by a Brown University alumnus



No comments:
Post a Comment